

- In the age of information, the ability to constantly monitor, understand and adapt to legal requirements – ideally before they are enforced – is a key asset for companies of all sizes.
Thousands of new regulations and recommendations are released every day around the world. Staying informed means being able to find the right provision contained in the correct legal document from any given country. To do this efficiently can be like searching for a needle in a haystack.
At Digicomply, we simplify the process by teaching machines to help humans. Whatever the operator’s level of expertise, Digicomply is able to help them to find the right provision and track any changes. Our aggregators collect up to a thousand new regulatory documents every day, covering every country in the world. The extent and complexity of this data means new tools had to be built to help distillate the flow of information. In this way, we have developed a systematic approach to the management and analysis of data relating to requirements and recommendations.
Text to Insight  Most of our documents are collected online from private repositories. In terms of analysis, one of the most difficult factors to overcome is the variety in document format, especially when it comes to tabular data in PDF documents. To solve this problem, all documents are pre-processed, cleaned, translated and then split into firstly sections and then sentences.
Most of our documents are collected online from private repositories. In terms of analysis, one of the most difficult factors to overcome is the variety in document format, especially when it comes to tabular data in PDF documents. To solve this problem, all documents are pre-processed, cleaned, translated and then split into firstly sections and then sentences.
The granularity of the information is one of the key pillars enabling conceptual searches. The other being the use of AI and its supporting infrastructure. Because our AI attentively ‘reads’ each word in each sentence and remembers its meaning, users can search beyond a basic reading of the document; accessing a new level of insight by conceptually linking sentences in a meaningful way to each enquiry.
Information Beyond Keywords
Intuitively, we all tend to simplify our queries when seeking information online to make sure the machine provides us with the most relevant information. Until recently, this was the only way to search because the technology mainly focused on keyword searches and synonym search expansion. These machines never truly ‘understood’ the meaning of our enquiries.
Instead, finding information relied on keyword statistics. To oversimplify this: the solution was to count the number of times a given document contained the inputted keyword(s). Traditional search engines were highly effective at searching for references, codes and specific statements, but were limited when it came to the kind of information and searches required by our users.
What confused traditional search engine algorithms were documents that:
- Used different words (synonyms, abbreviations, etc.)
- Didn’t contain simple affirmative forms – for example, used negations, questions, etc.
- Contained expressions and figures of speech
- Covered a large range of topics or information/facts
- Covered newer or less well known topics, where the user may not use the right technical terms
For example, if a user wanted to know if the US allows GMOs in organic products, the following enquiries might be formulated:
- “GMO organic food in USA”
- “Requirements organic products in USA”
- “Genetically modified organism organic USA”
- “Non-GMO US provisions”
While they all target the same topic and seek the same general information, traditional search algorithms would return a variety of different documents depending on the words in the query. For instance, some highly relevant documents might not contain the keyword ‘GMO’, instead relying on ‘genetically modified organism’. In this case, these documents would score low in searches for ‘GMO’.
Looking at it in reverse, the operator might mean very different things when searching for “GMO organic food in USA” and “GMO organic food from USA”, but traditional search engines wouldn’t recognize this different and would retrieve almost exactly the same set of documents.
Words to Concepts
The foundation of all our AI systems is a state-of-the-art deep universal language model that converts sentences into concepts and knowledge. Instead of processing each word independently – the traditional model – our universal language model considers each word in relationship to the words that surround it. This provides the necessary context for the machine to comprehend the original intent behind the query or document text – an unprecedented step forward in understanding.
Our extremely deep neural network captures the sense of the words in relation to each other, thanks to being trained in public and private text at a level way beyond the billion-word mark. To train machines to this level requires the latest hardware and we use several Google TPU (Tensor Processing Units) pods that enable a model to be trained in less than a week. To put this into perspective, training a standard office computer to the same efficiency would take roughly 12 years.
Sentence Highlighting
Some documents on the Digicomply platform exceed one thousand pages. Finding the right provision or fact within these documents is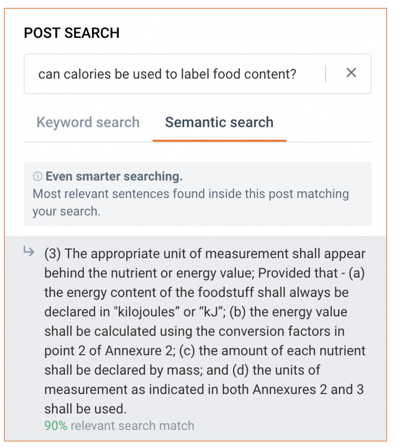 a tedious task. To help our users we built a solution that relies on the foundation deep conceptual language model to transform both the document sentences and the query into actionable machine understandable data.
a tedious task. To help our users we built a solution that relies on the foundation deep conceptual language model to transform both the document sentences and the query into actionable machine understandable data.
In the example below, the engine has understood the meaning of the enquiry and applied it to a given document. While the keyword ‘calories’ is not contained within the document, the conceptual engine has understood the user was referring to energy unit labeling and responded with the sentence in the document which best matches this understood intent. In comparison to the traditional search approach, which would only search for the specified keyword, the engine has used its learning to search an almost infinite number of queries related to “can calories be used to label food content?” and then combined the results for the user.

.webp?width=1644&height=1254&name=Food%20Safety%20Dashboard%201%20(1).webp)
